在这篇文章里,我们将尝试使用带有注意力机制的编码器-解码器(encoder-decoder)模型来解决序列到序列(seq-seq)问题
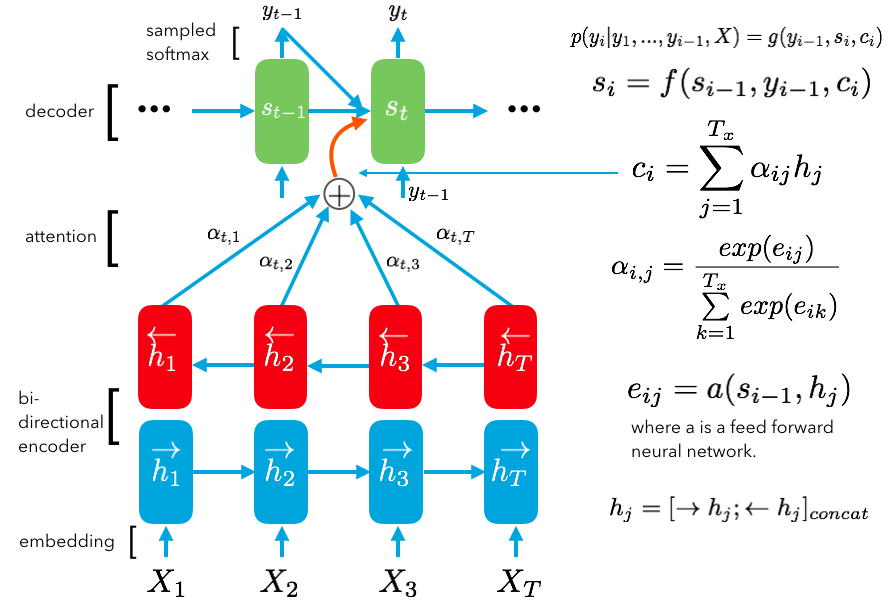
首先,让我们来一窥整个模型的架构并且讨论其中一些有趣的部分,然后我们会在先前实现的不带有注意力机制的编码器-解码器模型基础之上,添加注意力机制。我们将慢慢引入注意力机制,并实现模型的推断。。注意:这个模型并非当下最好的模型,更何况这些数据还是我在几分钟内草率地编写的。这篇文章旨在帮助你理解使用注意力机制的模型,从而你能够运用到更大的数据集上,并且取得非常不错的结果。
带有注意力机制的编码器-解码器模型:
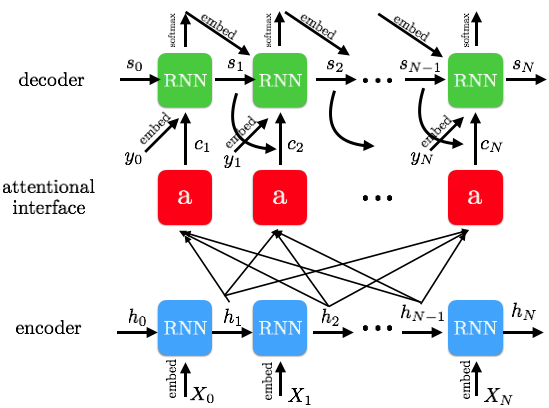
这张图片是第一张图的更为具体的版本,包含了更多细节。让我们从编码器开始讲起,直到最后解码器的输出。首先,我们的输入数据是经过填充(Padding)和词嵌入(Embedding)处理的向量,我们将这些向量交给带有一系列 cell(上图中蓝色的 RNN 单元)的 RNN 网络,这些 cell 的输出称为隐藏状态(hidden state,上图中的h0,h1等),它们被初始化为零,但在输入数据之后,这些隐藏状态会改变并且持有一些非常有价值的信息。如果你使用的是一个 LSTM 网络(RNN 的一种),我们会把 cell 的状态 c 和隐藏状态 h 一起向前传递给下一个 cell。对于每一个输入(上图中的 X0等),在每一个 cell 上我们都会得到一个隐藏状态的输出,这个输出也会作为下一个 cell 输入的一部分。我们把每个神经元的输出记作 h1 到 hN,这些输出将会成为我们注意力模型的输入。
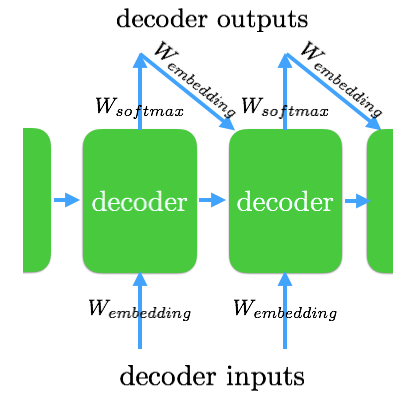
在我们深入探讨注意力机制之前,先来看看解码器是怎么处理它的输入以及如何产生输出的。目标语言经过同样的词嵌入处理后作为解码器的输入,以 GO 标识开始,以 EOS 和其后的一些填充部分作为结束。解码器的 RNN cell 同样有着隐藏状态,并且和上面一样,被初始化为零且随着数据的输入而产生变化。这样看来,解码器和编码器似乎没有什么不同。事实上,它们的不同之处在于解码器还会接收一个由注意力机制产生的上下文向量 ci作为输入。在接下来的部分里,我们将详细地讨论上下文向量是如何产生的,它是基于编码器的所有输入以及前面解码器 cell 的隐藏状态所产生的一个非常重要的成果:上下文向量能够指导我们在编码器产生的输入上如何分配注意力,来更好地预测接下来的输出。
解码器的每一个 cell 利用编码器产生的输入,和前一个 cell 的隐藏状态以及注意力机制产生的上下文向量来计算,最后经过 softmax 函数产生最终的目标输出。值得注意的是,在训练的过程中,每个 RNN cell 只使用这三个输出来获得目标的输出,然而在推断阶段中,我们并不知道解码器的下一个输入是什么。因此我们将使用解码器之前的预测结果来作为新的输入。
现在,让我们仔细看看注意力机制是怎么产生上下文向量的。
注意力机制:
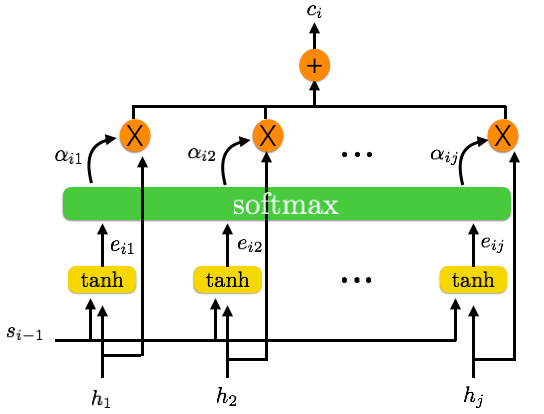
上图是注意力机制的示意图,让我们先关注注意力层的输入和输出部分:我们利用编码器产生的所有隐藏状态以及上一个解码器 cell 的输出,来给每一个解码器 cell 生成对应的上下文向量。首先,这些输入都会经过一层 tanh 函数来产生一个形状为 [N, H] 的输出矩阵e,编码器中每个 cell 的输出都会产生对应解码器中第 i 个 cell 的一个 eij。接下来对矩阵 e 应用一次 softmax 函数,就能得到一个关于各个隐藏状态的概率,我们把这个结果记作 alpha。然后再利用 alpha 和原来的隐藏状态矩阵 h 相乘,使得每个 h 中的每一个隐藏状态获得个权重,最后进行求和就得到了形状为 [N, H] 的上下文向量 ci,实际上这就是编码器产生的输入的一个带有权重分布的表示。
在训练开始,这个上下文向量可能会比较随意,但是随着训练的进行,我们的模型将会不断地学习编码器产生的输入中哪一部分是重要的,从而帮助我们在解码器这一端产生更好的结果。
Tensorflow 实现:
现在让我们来实现这个模型,其中最重要的部分就是注意力机制。我们将使用一个单向的 GRU 编码器和解码器,和前面那篇文章里使用的非常类似,区别在于这里的解码器将会额外地使用上下文向量(表示注意力分配)来作为输入。另外,我们还将使用 Tensorflow 里的 embedding_attention_decoder()接口。
首先,让我们来了解一下将要处理并传递给编码器/解码器的数据集。
数据:
我为模型创建了一个很小的数据集:20 个英语和对应的西班牙语句子。这篇教程的重点是让你了解如何建立一个带有软注意力机制的编码器-解码器模型,来解决像机器翻译等的序列到序列问题。所以我写了关于我自己的 20 个英文句子,然后把他们翻译成对应的西班牙语,这就是我们的数据。
首先,我们把这些句子变成一系列 token,再把 token 转换成对应的词汇 id。在这个处理过程中,我们会建立一个词汇词典,使我们能够从 token 和词汇 id 之间完成转换。对于我们的目标语言(西班牙语),我们会额外地添加一个 EOS 标识。接下来我们将对源语言和目标语言转换得来的一组 token 进行填充操作,将它们补齐至最大长度(分别是它们各自的数据集中的最长句子长度),这将成为最终我们要喂给我们模型的数据。我们把经过填充的源语言数据传给编码器,但我们还会对目标语言的输入做一些额外的操作以获得解码器的输入和输出。
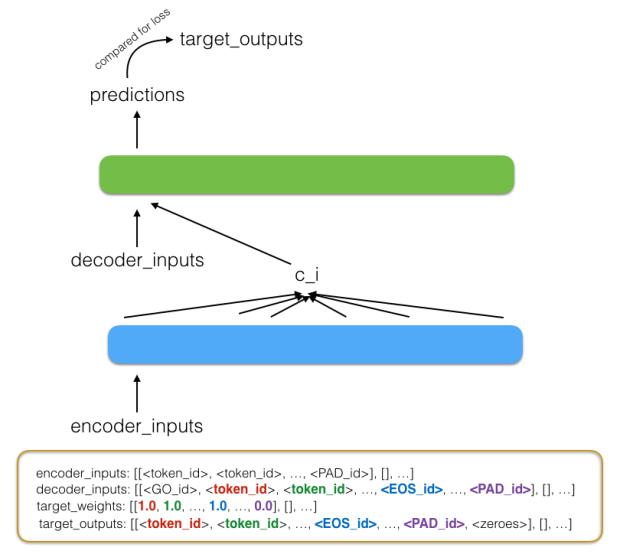
最后,输入就长成下面这个样子:

这只是数据集中的一个例子,向量里的 0 都是填充的部分,1 是 GO 标识,2 则是一个 EOS 标识。下图是数据处理过程更一般的表示,你可以忽略掉 target weights 这一部分,因为我们的实现中不会用到它。
编码器
我们通过 encoder_inputs 来给编码器输入数据。输入数据的是一个形状为 [N, max_len] 的矩阵,通过词嵌入变成 [N, max_len, H]。编码器是一个动态 RNN,经过它的处理之后,我们得到一个形状为 [N, max_len, H] 的输出,以及一个状态矩阵,形为 [N, H](这就是所有句子经 RNN 网络后最后一个 cell 相关的状态)。这些都将作为我们编码器的输出。
解码器
在讨论注意力机制之前,先来看看解码器的输入和输出。解码器的初始状态就是由编码器传递来的,每个句子经过 RNN 网络后最有一个 cell 的状态(形为 [N, H])。Tensorflow 的 embedding_attention_decoder() 函数要求解码器的输入是按先后顺序排列的(句子中词的先后)的列表,所以我们把 [N, max_len] 的输入转换为 max_len 长的列表 [N]。我们还使用经过 softmax 作用的权重矩阵处理解码器的输出,来创建我们的输出投影权重。我们将时序列表(即经过转换的 [N, max_len])、初始状态、注意力矩阵以及投影权重作为参数传递给 embedding_attention_deocder() 函数,得到输出(形状为 [max_len, N, H] *的输出以及状态矩阵 *[N, H])。我们得到的输出也是按时间先后排列的,我们将对它们进行 flatten 操作并且应用 softmax 函数得到一个形为 [N * max_len, C] 的矩阵。然后我们同样对目标输出进行 reshape 操作,从 [N, max_len] 变成 [N * max_len,] ,再利用 sparse_softmax_cross_entropy_with_logits() 来计算 loss 。接下来我们会对 loss 进行一些遮蔽操作,来避免填充操作对 loss 造成的影响。
注意力:
最后,总算到了注意力机制这一部分。我们已经知道了输入和输出,我们把一系列参数(时序列表、初始状态、注意力矩阵这些编码器的输出)交给了 embedded_attention_decoder() 函数,但在这其中究竟发生了什么?首先, 我们会创建一系列权重来对输入进行嵌入操作,我们把这些权重命名为 W_embedding。在通过输入生成解码器的输出之后,我们会开始一个循环函数,来决定将哪一部分输出交给下一个解码器作为输入。在训练过程中,我们通常不会把前一个解码器单元的输出传递给下一个,所以这里的循环函数是 None。而在推理期间,我们会这样做,所以这里的循环函数就会使用 _extract_argmax_and_embed(),它的用处就如它的名字所言(提取参数并且嵌入)。得到解码器单元的输出之后,让它和 softmax 后的权重矩阵相乘(output_projection),并将它的形状从 [N, H] 转换成 [N, C],再使用同样 W_embedding 来替代经过嵌入操作的输出([N, H]),再将经过处理的输出作为下一个解码器单元的输入。
1 | # 如果我们需要预测下一个词语的话,使用如下的循环函数 |
另外一个关于循环函数可选的参数是 update_embedding_ ,如果设置为 False,那么在我们对解码器的输出(GO token 除外)进行嵌入操作的时候,就会停止在 W_embedding 权重上使用梯度更新。因此,虽然我们在两个地方使用了 W_embedding,但它的值只依赖于我们在解码器的输入上使用的词嵌入而不是在输出上(GO token 除外)。然后,我们就可以把经过嵌入操作的时序解码器输入、初始状态、注意力矩阵以及循环函数交给 attention_decoder() 函数了。
attention_decoder() 函数是注意力机制的核心,这其中有一些额外的操作是文章开头那篇论文中没有提到的。回忆一下,注意力机制将会使用我们的注意力矩阵(编码器的输出)以及前一个解码器单元的状态,这些值将被传入一个 tanh 层,通过隐藏状态得到一个 e_ij(用来衡量句子对齐的程度的变量)。然后,我们将使用 softmax 函数将它转换为 alpha_ij 用于和与原始注意力矩阵相乘。我们对这个相乘之后的向量进行求和,这就是我们的新的上下文向量c_i。最终,这个上下文向量将被用来产生我们新的解码器的输出。
主要的不同之处在于,我们的注意力矩阵(编码器的输出)和前一解码器单元的状态不是简简单单通过一个 _linear() 函数能够处理,并且应用常规的 tanh 函数的。我们需要一些额外的步骤来解决这个问题:首先,对注意力矩阵使用一个 1x1 的卷积,这能够帮助我们在注意力矩阵中提取重要的 features,而不是直接处理原有的数据——你可以回想一下卷积层在图样识别中重要的特征提取作用。这一步能够让我们拥有更好的特征,但带来的一个问题就是我们需要用一个 4 维的向量来表示注意力矩阵。
1 | ''' |
这就意味着,为了处理经过转换的 4 维注意力矩阵和前一解码器单元状态,我们需要把后者也转换成 4 维的表示。这个操作很简单,只要将前一解码器单元的状态通过一个 MLP 的处理,就能把它变成一个 4 维的 tensor,从而匹配注意力矩阵的转换。
1 | y = tf.nn.rnn_cell._linear( |
将注意力矩阵和前一解码器单元的状态都进行过转换之后,我们就可以进行 tanh 操作了。我们将 tanh 后的结果和 softmax 得到的权重进行相乘、求和,再应用一次 softmax 函数得到 alpha_ij。最后,我们将 alphas 经过 reshape 后和初始注意力矩阵相乘,进行求和之后得到我们的上下文向量 c_i。
接下来就可以挨个地处理解码器的输入了。先讨论训练过程,我们不在乎解码器的输出因为输入最终都会变成输出,所以这里的循环函数是 None。我们将通过一个使用 _linear()函数的 MLP 以及前一个上下文向量来处理解码器输入(初始化为零),然后和前一个解码器单元的状态一起交给 dynamic_rnn 单元得到输出。我们一次处理所有样本数据的同一时刻的 token,因为我们需要从当时索引的最后一个 token 所对应的前一个状态。按时序排列的输入使我们在一批数据中这样做更为高效,这就是为什么我们需要输入变成一个时序列表的原因。
得到动态 RNN 的输出和状态之后,我们就能够根据新的状态计算出新的上下文向量。cell 的输出和新的上下文向量再通过一个 MLP,最终就能得到我们的解码器输出。这些额外的 MLP 并没有在解码器的示意图中画出,但他们是我们得到输出必要的额外步骤。值得注意的是,cell 的输出和 attention_decoder 的输出的形状都是[max_len, N, H]。
而当我们在进行推断的时候,循环函数不再是 None,而是 _extract_argmax_and_append()。这个函数会接收前一个解码器单元的输出,而我们新的解码器单元的输入就是先前的输出经过 softmax 之后的结果,接下来对它进行重嵌入操作。在利用注意力矩阵进行w完所有处理之后,将 prev 将被更新为新预测的输出。
1 | # 依次处理解码器的输入 |
然后,我们处理从 attention_decoder 得到的输出:使用 softmax 函数、进行 flatten 操作,最后和目标输出进行比较并计算 loss。
细节:
Sampled Softmax
在机器翻译这样的序列对序列的任务上使用注意力机制模型的效果是非常出色的,但常常因为语料库的巨大带来问题。特别是在我们训练时,计算解码器的输出的 softmax 是非常耗费资源的,解决的办法就是使用 sampled softmax
下面是 sampled softmax 的代码,注意这里的权重和我们在解码器上使用的 output_projection 是一样的,因为使用它们的目的都是相同的:把解码器的输出(长度为 H 的向量)转换成对应类别数量长度的向量。
1 | def sampled_loss(inputs, labels): |
接下来,我们可以利用 seq_loss 函数来计算 loss,其中的权重向量除了目标输出为 PAD token 的部分是 0,其他都是 1。值得注意的是,我们只会在训练过程中使用 sampled softmax,而在进行预测的过程中,我们会对整个语料库进行采样,使用常规的 softmax,而不仅仅只是一部分最为近似的语料。
1 | else: |
带有 buckets 的模型:
另外一种常见的附加结构是使用 tf.nn.seq2seq.model_with_buckets() 函数,这种 buckets 模型的优点在于缩短了注意力矩阵向量的长度。在先前的模型中,我们会把注意力向量应用在 max_len 长度的 hidden states 上。而在这里,我们只要对相关的一部分应用注意力向量,因为 PAD token 是完全可以被忽略的。我们可以选择对应的 buckets 使得句子中的 PAD token 尽可能的少。
但我个人觉得这个方法有一点粗糙,而且如果真的想要避免处理 PAD token 的话,我会建议使用 seq_lens 这个属性来过滤掉编码器输出中的 PAD token,或者当我们在计算上下文向量的时候,我们可以把每个句子中 PAD token 对应的 hidden state 置为 0。这种方法有点复杂,所以我们不在这里实现它,但 buckets 对于 PAD token 带来的噪音确实不是一种优雅的解决方法。
总结:
注意力机制是研究的一个热门,并且也存在很多变种。无论在什么情况下,这种模型在序列对序列的任务上总是能有非常出色的表现,所以我非常喜欢使用它。请谨慎地分割训练集和验证集,因为这种模型很容易过拟合从而在验证集上产生非常糟糕的表现。在接下来的文章里,我们会使用注意力机制来解决设计内存和逻辑推理的更为复杂的任务。
矩阵形状分析:
编码器的输出形为 [N, max_len],经过嵌入操作之后转变为 [N, max_len, H],然后交给编码器 RNN。编码器的输出形为 [N, max_len, H],状态矩阵形为 [N, H],其中包含了各个样本最后的 cell 的状态。
编码器的输出和注意力向量的形状都是 [N, max_len, H]。
解码器的输出形为 [N, max_len],会被转换为一个 max_len 长度的时序列表,其中每个向量的形状为 N。解码器的初始状态就是编码器形为 [N, H] 的状态矩阵。在将数据输入解码器 RNN 之前,数据会被进行嵌入操作,变成一个 max_len 长度的时序列表,其中的每个向量形状为 [N, H]。输入数据可能是真实的解码器输入,或者在进行预测的时候,就是由前一个解码器 cell 产生的输出。前一个解码器 cell 在前一刻产生的输出形为 [N, H],将经过一层 softmax 层(输出投影)而变成 [N, C]。然后使用我们在输入上使用的权重向量,再一次进行嵌入操作变回 [N, H]。这些输入将被喂给解码器 RNN,从而产生解码器形为 [max_len, N, H] 的输出以及状态矩阵 [N, H]。输出将被进行 flatten 操作而变成 [N* max_len, H] 并且和同样经过 flatten 操作的目标输出进行比较(同样形为 [N* max_len, H])。如果目标输出中有 PAD token 的话,在计算 loss 的时候会进行一些遮蔽操作,接下来就是 backprop 了。
在解码器 RNN 内部,同样有一些形状转变的操作。首先注意力向量(编码器输出)形为 [N, max_len, H],将被转化为一个 4 维的向量 [N, max_len, 1, H](这样我们就可以使用卷积操作了)并且利用卷积来提取有用的特征。这些隐藏特征的形状也是 4 维,[N, height , 3, H]。解码器的前一隐藏状态x向量,形为 [N, H],同样是注意力机制的一个输入。这个隐藏状态向量经过一个 MLP 变成 [N, H] (这么做的原因是为了防止前一隐藏状态的第二维(H)和 attention_size 不同,在这里同样是 H)。接下来这个隐藏状态向量同样被转换成一个 4 维向量 [N, 1, 1, H],这样我们就可以将它和隐藏特征相结合。我们对相加的结果使用 tanh 函数,再通过 softmax 函数得到 alpha_ij,其形状为 [N, max_len, 1, 1] (这代表了每个样本中各个隐藏状态的概率)。这个 alpha 和原始的隐藏状态相乘,得到形为 [N, max_len, 1, H]的向量,再进行求和得到形为 [N, H] 的上下文向量。
上下文向量和解码器的形为 [N, H] 的输入结合,无论这个输入是来自解码器的输入数据(训练时候)还是来自前一个 cell 的预测(预测时候),这个输入只是长度为 max_len 列表中形为 [N, H] 向量的其中一个。首先我们让它和前一个上下文向量相加(初始化为全 0 的 [N, H] 矩阵),回想一下我们的来自于解码器输入的数据是一个时序列表,长度为 N,其中的向量形为 [max_len, ],这就是为什么输入的形状都是 [N, H]。相加的结果将经过一层 MLP,得到一个形为 [N, H] 的输出,这和状态矩阵(形状为 [N, H])将被交给我们的动态 RNN cell 。得到的输出 cell_outputs 形为 [N, H],并且状态矩阵同样为 [N, H]。这个新的状态矩阵将会成为们下一个解码器的输入。我们对 max_len 个输入进行这样的操作,从而得到了一个长度为 max_len 的是列表,其中的向量都是 [N, H]。在从解码器得到这个输出和状态矩阵之后,我们将新的状态矩阵传给 attention 函数得到新的上下文向量,新的上下文向量形为 [N, H],并且和形为 [N, H] 的输出相加,再一次应用 MLP,转换成形为 [N, H] 的向量。最后,如果我们在进行预测,新的 prev 将会成为我们的最终输出(prev 初始为 none)。prev 将会成为 loop_function 的输入,来得到下一个解码器的输出。